
Paraphrase Generation: A survey of the State of the Art
1. Introduction
Paraphrasing 은 different words 나 sentence strctures 를 통하여 같은 의미를 가지는 문장을 생성해내는 것을 목표로 한다.
ex) How do I improve my English -> What is the best way to learn English
해당 review paper 의 purpose 는 다음과 같다.
- introduce the most frequently used datasetsd for paraphrase generation section2
- list the traditional evaluation metrics section3
- present some of the traditional approaches used before nerual method section4
- neural model methods section5
- model 들의 performance comparison section6
- Identify some research gaps in paraphrase generation section7
2. Datasets
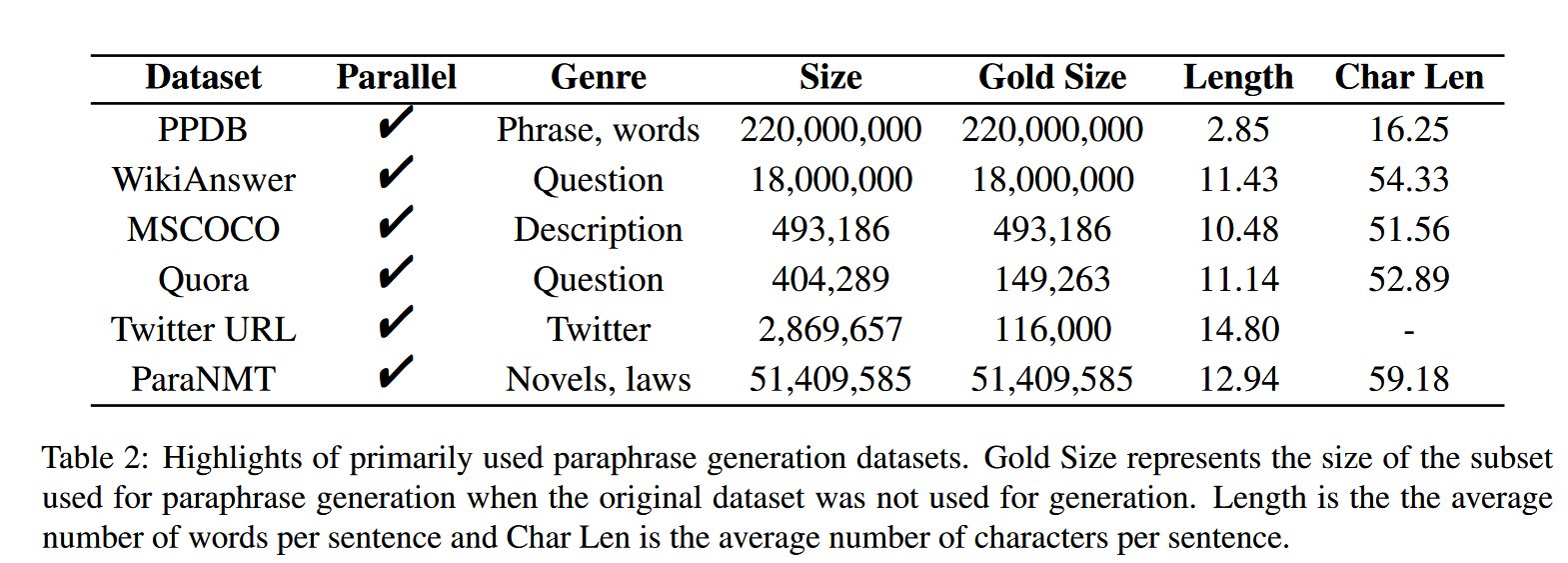
PPDB
PPDB는 each paraphrase pair paraphrase probabilities 와 monolingual distributional simility scores 를 포함한 set of associated scores 를 제공한다.
하지만 senetence paraphrase 가 paraphrase pair 에 존재하지 않아 사용 빈도가 줄어들고 있다.
WikiAnswer
WIKIAnswer 는 the synonyms in the parphrase sentences 와 연관되어 있는 word-alignment 를 제공한다.
하지만 dataset 이 question pair 만 제공하기에 사용 범위가 restrict 하다.
MSCOCO
MSCOCO 는 Large-scale object detection 에서 5명의 다른 human annotator 들이 120k 개의 그림에 대해서 , 5개의 caption 을 달게 되었고 이들이 parphrase pair로서 쓰이게 된다.
In most cases 에서 annotator 들은 image의 prominent object/action 을 묘사하여 caption 들이 통일성을 가지고 있고 , dataset 이 paraphrase-related task에 적합하다고 볼 수 있다.
Quora
Quora 는 2017에 relsead 된 dataset 으로써 400K가 넘는 potential question duplicate pair 를 포함하고 있다. 이중 150k의 question pairs 가 paraphrase 로 annotated 되었고, 이 valid question pairs 가 training과 testing 에 쓰일 수 있다.
단점은 WikiAnswer 과 유사하게 question paraphrase 로 사용 범위가 한정된다.
Twiter URL
Twtter URL은 Shared url을 linking 하는 과정에서 발생하는 tweet 들을 collect 하여, large-scal sentential paraphrase 를 construct 하였다. Human-annotator 가 분류한 paraphrase 만 사용할 수 있다.
ParaNMT
ParaNMT 는 50-million 이상의 English-English sentential paraphrase pairs 이다. 해당 데이터는 English parallel corpus 를 non-english 를 pivot으로 번역한 후 , 이를 재 번역하여 만들어 졌다.
3. Evaluation
Automatic Evaluation
- BLEU : originally developed to evaluate machine tralslation , n-gram 기반
- METEOR : aims to address BLEU’s weakness
- Low-resource language 에서 semntic equivalent 를 측정할 수 없음
- sentence/segment Level 에서 BLEU 는 low judgement 를 가지고 있음
- ROUGE : text summarization 을 위해 developed 되었지만 , paraphrase generation 에서도 사용
- TER : machine translation 을 evaluation 하기 위해 개발 되었지만 paraphrase evaluation 에서도 사용
human translator 가 ouptut translation 을 reference trnaslation 으로 바꾸기 위해서 어느 정도 change 해야 하는가 -> lower is better
Human Evaluation
automatic evaluatio metric 이 semantic 비교 보다 evaluation metrics 에 mainly focus 하기에 , human evaluation 이 generated output 에 대하여 보다 accurate 하고 qualitive 한 evaluation 이 가능하다.
평가 기준은 similarity , clarity , fluency 가 있으며, 더 많은 cost 가 들지만 represintitive 하다.